personal blog of Gaurav Ramesh
Engineering Behind Fast Analytics - A Detour into Data in Motion
In our last post, we explored how columnar storage revolutionizes analytical workloads. But even with perfectly organized columnar data, there are still inefficiencies in other parts of the stack that remain to be optimized. So let's set aside columnar storage for a bit(we'll come back to it in a later post), and consider something more fundamental - storage is only part of the picture.
Storage is Data at Rest. What About Data in Motion?
We usually think of databases as storing data in disk. But to reap the full benefits of columnar storage, data also needs to be represented in a similar manner in memory. And besides, storing data in columns is looking at data at rest. In real workflows, data rarely just sit quietly on disk, or in memory. It needs to move - from storage to memory, between processes, or threads within the same system, across networks to different systems. In other words, data constantly crosses boundaries. And when it does, it undergoes transformations, technically called serialization and deserialization.
Not at all boundaries are created equal though:
- network boundaries(different machines) always require serialization
- process boundaries(same machine, different memory spaces) usually do too
- thread boundaries(same process, but concurrent access) sometimes require it
- function boundaries(same process, different functions) rarely require serialization
- memory-disk boundaries require it
But what does serialization mean, and why do we need it? To understand why data movement requires serialization and deserialization, we need to examine a fundamental challenge: how data is stored in memory and why it can't simply be moved as-is.
The Memory Layout Problem
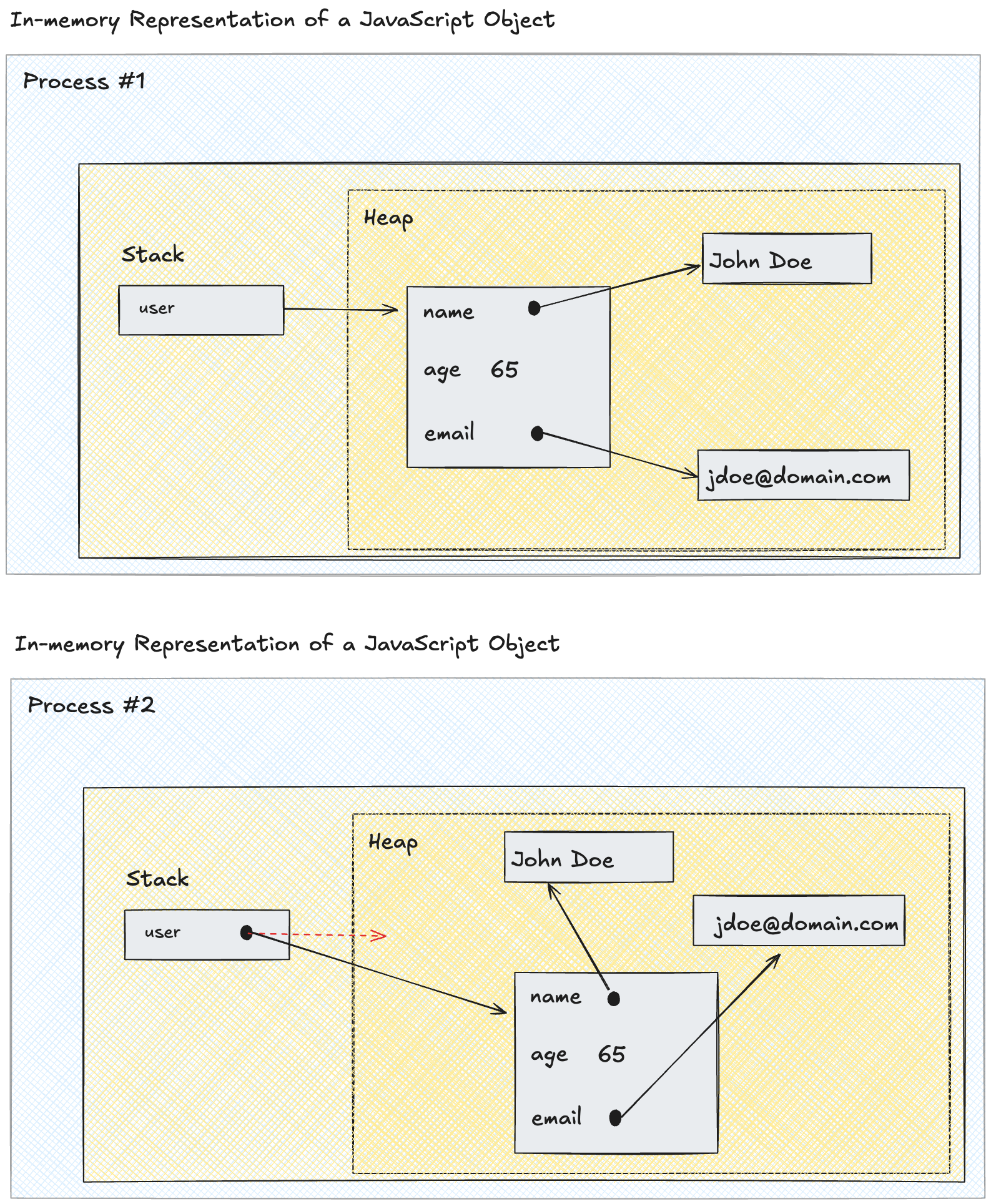
Consider a simple example of a user object as shown below, with properties name, age and email, as it's stored in memory. In most languages, objects are stored in the heap space, with pointers to them in the stack, while primitives are stored inline. While this kind of random access works in memory, we encounter problems as the data starts to move
Why Pointers Don't Travel
Pointers to other locations don't make sense over the network and in disk. One, they are not random access mediums and so can't just jump to a random location, and two, because machines on different ends of the network may have different architectures. And each process within a system typically works in a virtual memory space, so the pointers to "absolute" locations don't point to the same things in a different process within a different memory space. In other words, the heap allocations for the different objects will be in completely different locations in different memory spaces.
So while all variables are indeed represented as bytes in memory, you can't simply dump these bytes to a file and call it "serialized" because objects are often scattered across different memory locations connected by pointers.
user = {
name: "John Doe",
age: 65,
email: "jdoe@domain.com"
}
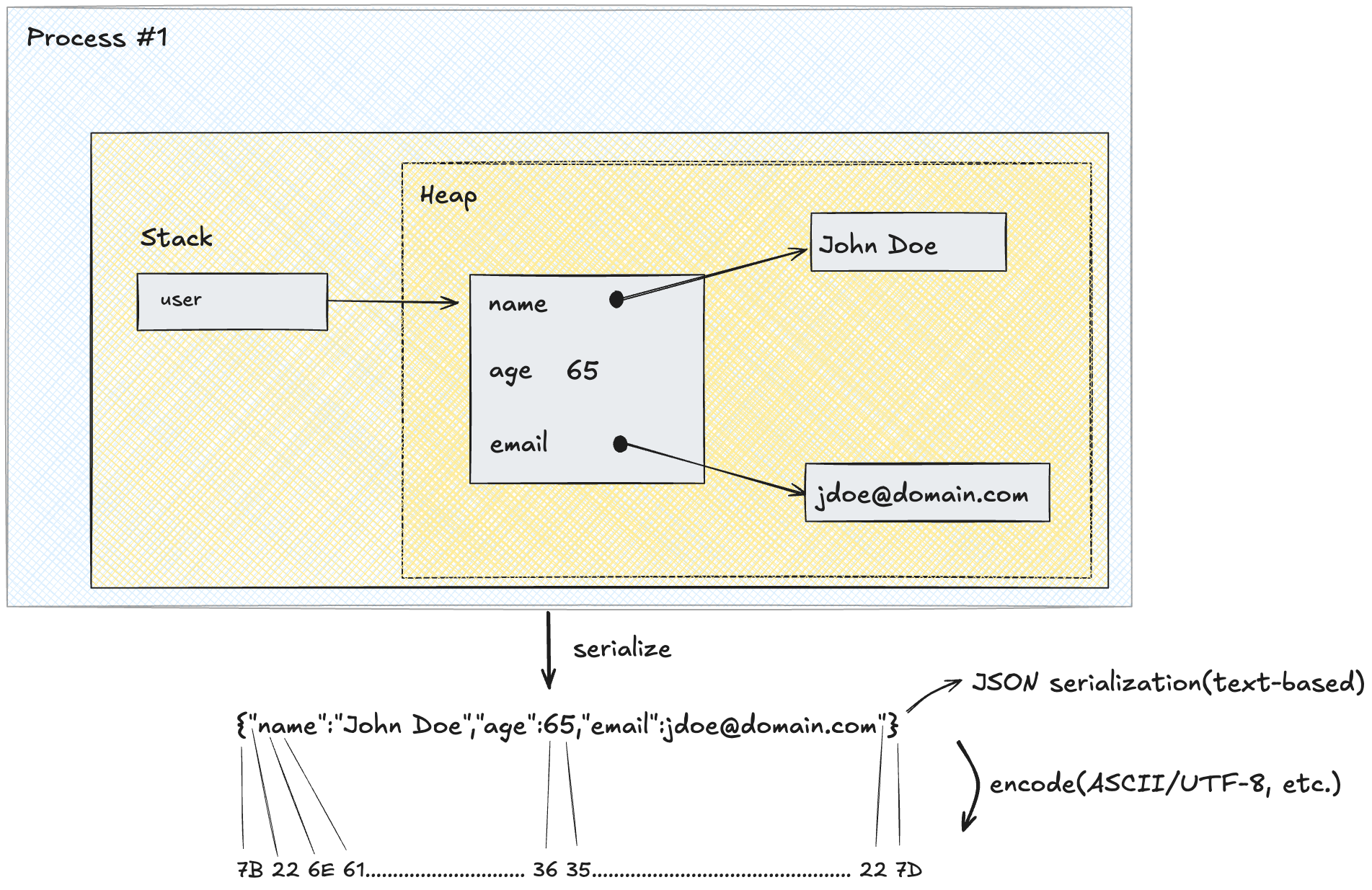
To address both of those issues, we need a way to convert the complex object graphs in memory to a simpler, serial format that can be reconstructed back to its original shape and form. That is, we need to serialize them.
This is how we'd serialize the user object in JSON.
Text-based and Binary Serialization
JavaScript objects, like POJOs in Java, are in-memory representations of objects. And while JSON looks like JavaScript object, it's actually a text-based serialization format, like XML, CSV, YAML and others. They are called text-based because their underlying byte encodings represent the individual printable characters you see on the screen. As shown in the example above, every character of a JSON object is encoded in hex and then in binary.
Char: { " n a m e " : " J o h n " , " a g e " : 6 5 }
Hex: 7B 22 6E 61 6D 65 22 3A 22 4A 6F 68 6E 22 2C 22 61 67 65 22 3A 36 35 7DText-based serialization is well-suited when the amount of data being dealt with is relatively small, and/or is primarily being processed for display purposes. In most applications, the clients fetch the data from the server to display it to the user, so it makes sense why you see "application/json" in Content-type and Accept-type headers in APIs all over.
It's used primarily because it is human-readable, easy to debug, simple to make sense of and have wide support. But it comes at the cost of transport and processing inefficiencies.
What inefficiencies?
In text-based formats, all characters are encoded in isolation, so in a way, they are "what you see is what you store" formats. For instance, the age value 65 is encoded using the characters '6' and '5', requiring two bytes of storage. A binary format could represent this number as a single 8-bit integer, using just one byte. A boolean value of "true" will be encoded in four letters: "t", "r", "u", "e", where 1 byte can suffice. And not to mention, the keys(name, age and email) are repeated with every object which takes up a lot of space.(Compression techniques like gzip help with this).
It not only takes a lot of space, but makes processing of the data harder on the other end, while deserializing because it has to be read linearly, one character after another.. so we can't tell that the number 65 is 65 until we read both the characters "6" and "5". That's true for binary values too. And while compression solves for the transport inefficiencies, it adds more processing overhead, because besides reading linearly, the receiving system has to first uncompress the data.
A Side Note on Why Hex Codes are Used
Hex codes are used to represent bytes because they provide a much more compact and readable way to display binary data compared to the alternatives. A byte contains 8 bits, which means it can represent 2^8 = 256 different values (0-255). Hexadecimal uses base-16, and since 16^2 = 256, exactly two hex digits can represent any possible byte value. This creates a perfect 1:1 mapping where every byte = exactly 2 hex digits. The "0x" prefix is primarily used to indicate to the reader that the symbols represent hex codes and not decimal. e.g. 41 might be confused with the number forty-one, but 0x41 indicates byte code for the letter 'A'.
Binary serialization store data as the actual bytes that represent the data directly. While a number 30 is stored as characters '3'(hexcode:0x33) and '0'(hexcode:0x30) in a text-based format, they are represented directly as the number 30(hexcode:0x1E) in native data types like unsigned 8-bit integers(uint8). Protobufs are an increasingly popular binary-serialization format widely in use today. Our above user example will be defined in Protobuf by a schema that looks like the following:
message User {
string name = 1;
int32 age = 2;
string email = 3;
}The number representations for fields helps store them efficiently, while the data will be encoded something like this:
0a 08 4a 6f 68 6e 20 44 6f 65 10 41 1a 0f 6a 64 6f 65 40 64 6f 6d 61 69 6e 2e 63 6f 6dwhich will be interpreted roughly as this:
[tag(field type)][(optional)length][actual data]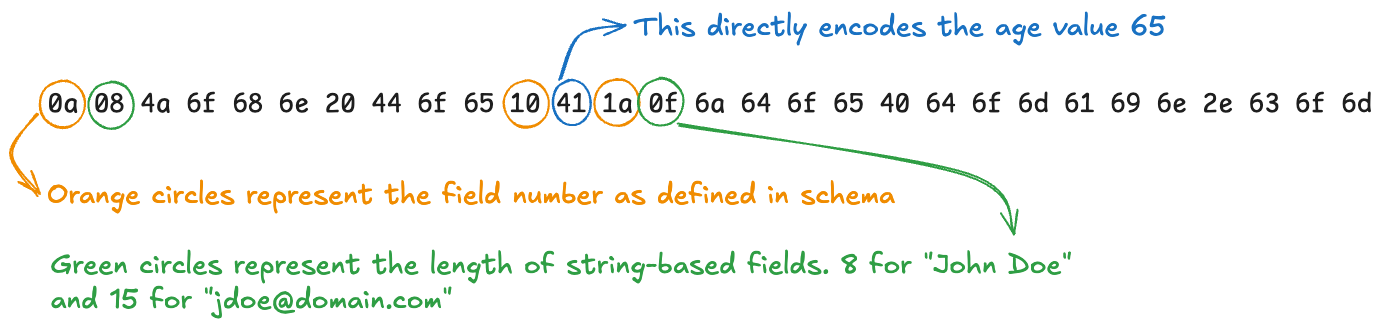
Two key observations to be made here:
- Data is now self-describing, that is, unlike with JSON, where the parser had to see '6', '5' and then double-quotes to understand that 65 is the age, with protobufs, the type, indicated by "10" above, tells that the age is encoded in 1 subsequent byte, so it knows that the value 41(which is hex code for decimal 65) represents the age(This is a simplification of how protobufs work, but good enough to illustrate the point).
- It is much more compact - 30 bytes(43% smaller!) vs 53 bytes for JSON
Binary serialization formats solve for the inefficiencies of the text-based formats, but at the cost of human-readability and the ability to debug, which means they are ideal for cases where they are either meant for machine processing(we'll come to this point in a later post), or when we're dealing with a large amount of data.
Okay, but why do we need to know about serialization and deserialization to build fast analytical systems? Good question. Now that we've seen de/serialization, let's look at how data moves in a typical client-server request/response flow.
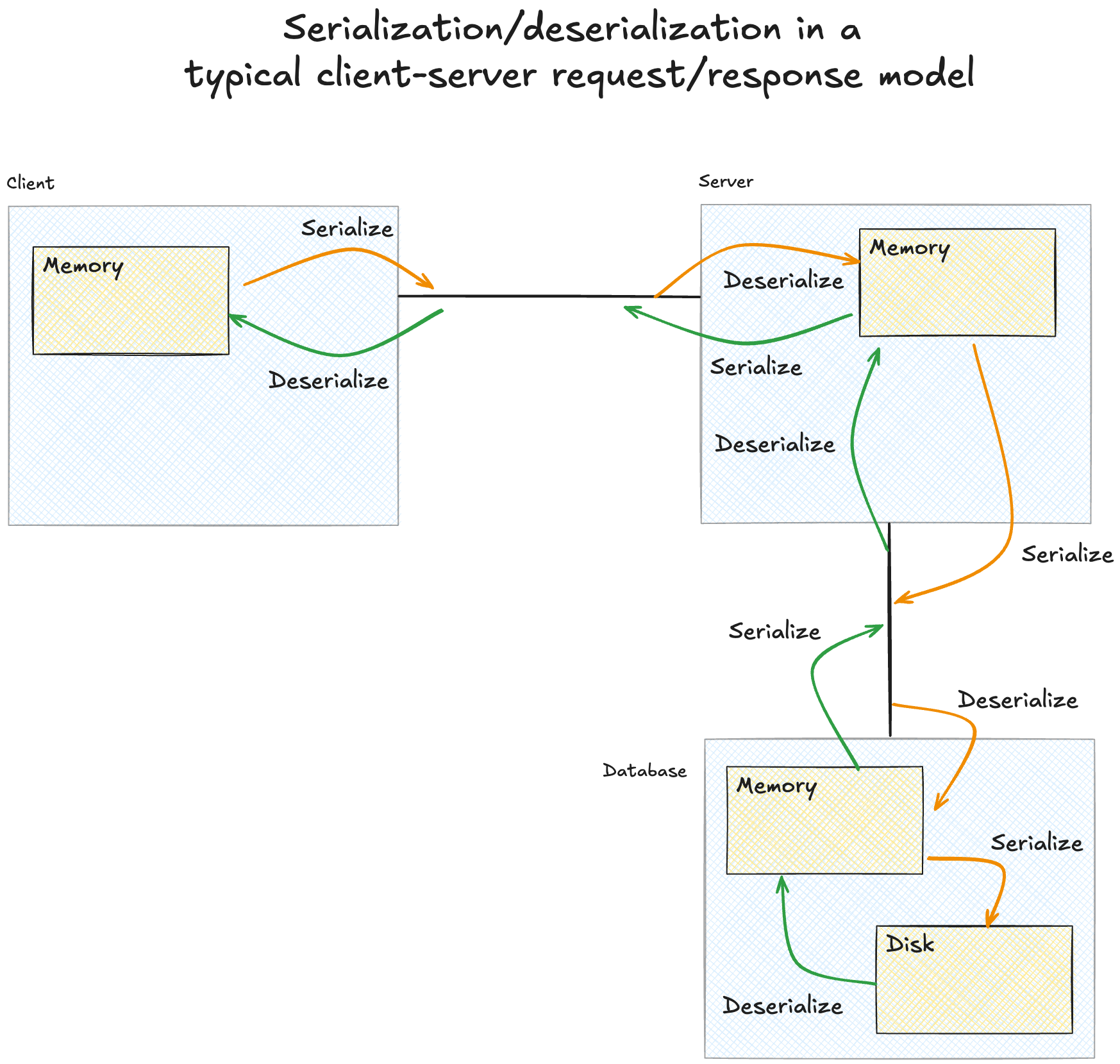
As you can see, the story of data in motion is a story of serialization/deserialization! Every request involves moving data between storage tiers, across network boundaries, and between processing nodes. Each boundary crossing triggers translation and requires paying a "translation tax", which is important, but not quite as consequential in transactional systems where we move single entities, like the user entity from the previous examples. Analytical systems often process millions of such objects. At that scale, these inefficiencies compound into significant performance bottlenecks.
In conclusion: data must move, movement requires serialization, serialization is expensive, and analytics amplifies this cost. In the next post, we'll explore some of the technologies that minimize these serialization costs through innovative techniques.
Share or Subscribe
Get notified when new posts are published. Once a month, I share thoughtful essays around the themes of personal growth, health & fitness, software, culture, engineering and leadership — all with an occassional philosophical angle.